이게 배포한 API가 MariaDB를 사용중인데 조금 더 효율적인 DB가 없을까 생각을 하게 됨.
그래서 대규모 데이터셋에서의 읽기/쓰기 성능이 뛰어나다는 PostgreSQL을 적용해보고 테스트, 그리고 그래프로 표시를 해볼까? 싶어서 한번 해보기로 했음.
MariaDB도 처음부터 쓴게 아니고 MySql을 사용했었는데 대규모 데이터셋은 MariaDB의 InnoDB가 트렌젝션을 안전하게 처리하고, 동시성 제어가 뛰어나다는 정보를 들어서 채용해서 사용중이였음.
그래서 이미 DB를 한번 바꿔본 전적이 있는데 내가 이걸 서술을 했었는지 안했었는지 기억이 안남..
여튼 지금은 MariaDB과 PostgreSQL의 비교를 해보고 유의미한 차이가 있다면 PostgreSQL로 갈아탈 수도? 있는 글을 작성할거임.
일단은 내 프로젝트에 맞게 연결부터 해줘야함. 마리아는 연결되어있으니까 PostgreSQL연결하고 docker-compose에도 컨테이너 띄워보자.
아차차 Flask-SQLAlchemy도 PostgreSQL과 호환되는지 확인하고 테스트하는거임.
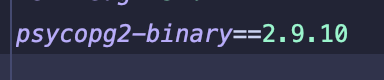
여튼 requirements.txt에 추가해주고,
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://postgres:1234@postgres_container:5432/STAR_INFO_API_DB'연결해주고,
postgres_db: # 테스트용 PostgreSQL 추가
image: postgres:14
container_name: postgres_container
ports:
- "5432:5432"
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: "1234"
POSTGRES_DB: STAR_INFO_API_DB
volumes:
- postgres_data:/var/lib/postgresql/data
healthcheck:
test: [ "CMD-SHELL", "pg_isready -U postgres" ]
interval: 10s
retries: 3
networks:
- my_network도커 컴포즈에서도 추가해줌.
그리고 기존 __init__은 주석 처리하고 아래 새롭게 DB 설정을 추가함. 엔드포인트로 요청하면 해당 DB로 설정되게끔.
그리고 db_type 이라는 변수를 만들어서 엔드포인트에 DB 이름 입력시에 변경되도록 설계함.
그리고 그 요청을 하면 쓰기, 읽기, 수정, 삭제 순으로 알아서 돌아가게끔 했음..
일단 준비는 했으니까 JMeter 다운 받아보자.

난 여기서 tgz 파일로 받았음.
아 이러면 명령어로 실행이 안되네.
brew install jmeterbrew로 받음.

설치 잘 됐음.
실행창이다.
그래서 어떤 방식으로 테스트가 진행되냐,
빌드할 때 DB를 골라서 진행함.
DB_TYPE=mariadb docker-compose up --build이렇게 빌드 이후에 테스트 엔드포인트로 요청을 보내면 JMeter가 .cvs 파일을 생성할거고 나중에 이 파일로 그래프를 그리는 로직을 짜서 비교해보면 되는거.
그래서 JMeter에서 이에 대한 설정을 좀 해주자고.
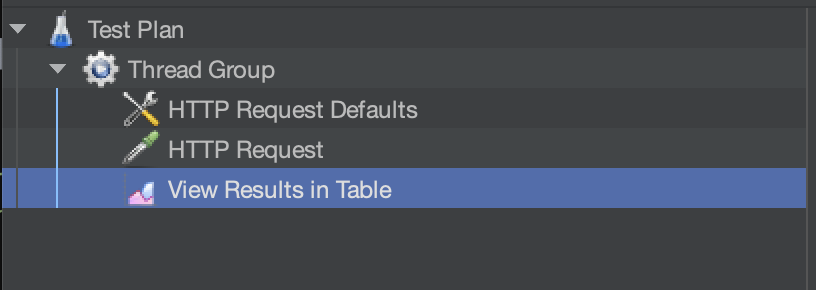
내가 생성한 것들이고,
HTTP Request Defaults와 HTTP Request 에서 요청에 대한 설정을 해줌. HTTP Request에서 인서트, 쿼리, 업데이트, 딜리트로 바꿔주면서 테스트 해보고, 그 결과를 View Results in Table에서 .cvs를 저장하면 됨.
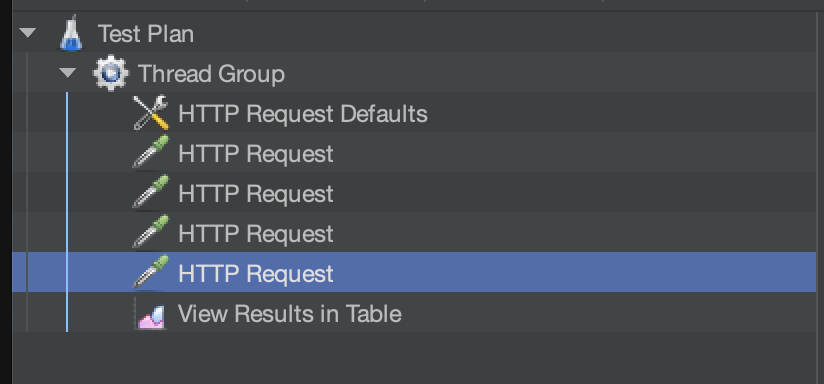
최종적으로 모든 CRUD가 한번에 돌아가게끔 4개의 요청을 보낼 수 있게 했고..
혹시 테스트로 삽입된 데이터가 제대로 정리 되지 않을 수도 있어서 delete 쿼리는
if target_value:
session.execute(f"DELETE FROM {TABLE_NAME} WHERE value > :target_value", {"target_value": target_value})
elif created_after:
session.execute(f"DELETE FROM {TABLE_NAME} WHERE created_at >= :created_after", {"created_after": created_after})
else:
session.execute(f"DELETE FROM {TABLE_NAME}")이렇게 했음.
그럼 이제 요청을 보내봐야지
이게 지금 하나의 메서드에서 두개의 DB를 처리하고 싶어서 기존 세션 연결 방식들을 조금 고치느라 오래걸렸다.
기존 쓰던거 주석 처리 이후에 변수로 DB 이름을 받게끔 설계했고,
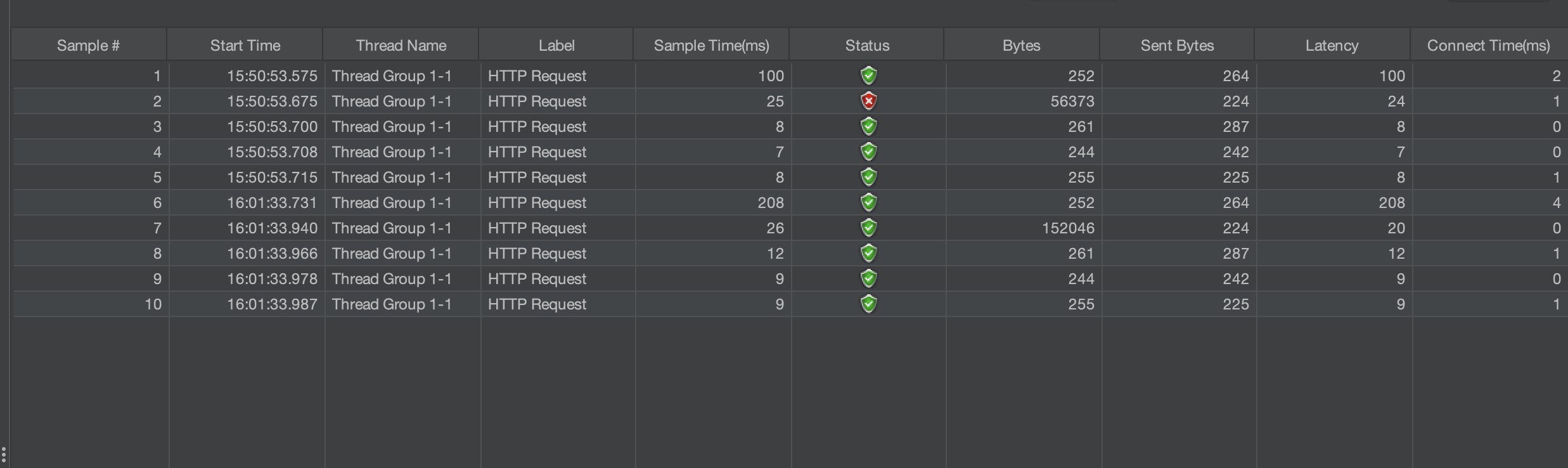
이제는 오류 없이 작동한다. 저 위에 빨간놈은 읽기에서 오류가 생겨서 수정해봄. 이제 PostgreSQL도 오류가 안나면 대량으로 요청해서 .csv 파일을 남기면 된다.

오케이 PostgreSQL도 문제 없구만.
그럼 PostgreSQL부터 대량으로 테스트 시작하면 되겠다.
일단 핵심 코드만 보면
# app/routes/db_test_routes.py
from flask_restx import Namespace, Resource
from flask import Blueprint, request
from app.db.db_utils import get_session
import random
import string
from datetime import datetime
from sqlalchemy.sql import text
# Namespace 등록
db_test_ns = Namespace('db_test', description="Database Test Operations")
# Blueprint 등록
db_test_blueprint = Blueprint('db_test', __name__, url_prefix='/perform')
TABLE_NAME = "test_data"
def ensure_table_exists(session, db_type):
"""
테이블이 없으면 생성하는 함수 (DB 연결 확인 포함)
"""
try:
# DB 연결 확인용 간단한 쿼리
session.execute(text("SELECT 1"))
except Exception as e:
raise RuntimeError(f"Database connection failed: {str(e)}")
if db_type == "mariadb":
create_table_query = text(f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
value INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
""")
elif db_type == "postgres":
create_table_query = text(f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
id SERIAL PRIMARY KEY,
name VARCHAR(255),
value INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
""")
else:
raise ValueError(f"Unsupported database type: {db_type}")
session.execute(create_table_query)
session.commit()
def drop_table(session, db_type):
"""
테이블 삭제 함수
"""
print(f"Attempting to drop table {TABLE_NAME} in {db_type}.")
if db_type in ["mariadb", "postgres"]:
drop_table_query = text(f"DROP TABLE IF EXISTS {TABLE_NAME};")
else:
raise ValueError(f"Unsupported database type: {db_type}")
session.execute(drop_table_query)
session.commit()
print(f"Table {TABLE_NAME} dropped in {db_type}.")
# Flask Blueprint - 단순 View Function
@db_test_blueprint.route('/<string:db_type>', methods=['POST'])
def perform_operations(db_type):
"""
Perform operations using PerformOperations class.
"""
print(f"Request received for /perform/{db_type} using Blueprint.")
operations_instance = PerformOperations()
return operations_instance.post(db_type)
# Flask-RestX Resource - Namespace
@db_test_ns.route('/perform/<string:db_type>')
class PerformOperations(Resource):
def post(self, db_type):
"""
통합 테스트 엔드포인트 - 삽입, 조회, 수정, 삭제 작업 수행
"""
print(f"Request received for /perform/{db_type} using Namespace.")
try:
data = request.json
print(f"Received data: {data}")
operation = data.get("operation")
params = data.get("params", {})
print(f"Operation: {operation}, Params: {params}")
with get_session(db_type) as session:
# 테이블 생성 확인 및 생성
print("Ensuring table exists...")
ensure_table_exists(session, db_type)
if operation == "insert":
print("Performing INSERT operation...")
num_rows = params.get("rows", 1000)
data_to_insert = [
{
"name": ''.join(random.choices(string.ascii_letters, k=10)),
"value": random.randint(1, 1000),
"created_at": datetime.utcnow()
}
for _ in range(num_rows)
]
session.execute(text(f"""
INSERT INTO {TABLE_NAME} (name, value, created_at)
VALUES (:name, :value, :created_at)
"""), data_to_insert)
session.commit()
print(f"{num_rows} rows inserted into {TABLE_NAME}.")
return {"message": f"{num_rows} rows inserted into {db_type}."}, 200
elif operation == "query":
print("Performing QUERY operation...")
result = session.execute(text(f"SELECT * FROM {TABLE_NAME};")).fetchall()
print(f"Query result: {len(result)} rows fetched.")
# Row 데이터를 JSON 직렬화 가능하도록 변환
def serialize_row(row):
row_dict = dict(row._mapping) # _mapping 사용
# datetime 객체를 문자열로 변환
for key, value in row_dict.items():
if isinstance(value, datetime):
row_dict[key] = value.isoformat() # ISO 8601 형식
return row_dict
return {
"rows": len(result),
"data": [serialize_row(row) for row in result] # 직렬화된 데이터 반환
}, 200
elif operation == "update":
print("Performing UPDATE operation...")
target_value = params.get("value", 500)
new_value = params.get("new_value", 999)
session.execute(text(f"""
UPDATE {TABLE_NAME}
SET value = :new_value
WHERE value > :target_value
"""), {"new_value": new_value, "target_value": target_value})
session.commit()
print(f"Rows with value > {target_value} updated to {new_value}.")
return {"message": f"Rows with value > {target_value} updated in {db_type}."}, 200
elif operation == "delete":
print("Performing DELETE operation...")
target_value = params.get("value", None)
created_after = params.get("created_after", None)
if target_value:
session.execute(text(f"DELETE FROM {TABLE_NAME} WHERE value > :target_value"),
{"target_value": target_value})
print(f"Rows with value > {target_value} deleted.")
elif created_after:
session.execute(text(f"DELETE FROM {TABLE_NAME} WHERE created_at >= :created_after"),
{"created_after": created_after})
print(f"Rows created after {created_after} deleted.")
else:
session.execute(text(f"DELETE FROM {TABLE_NAME}"))
print("All rows deleted.")
session.commit()
return {"message": f"Rows deleted in {db_type}."}, 200
elif operation == "drop":
print("Performing DROP operation...")
drop_table(session, db_type)
return {"message": f"Table {TABLE_NAME} dropped in {db_type}."}, 200
else:
print("Invalid operation specified.")
return {"error": "Invalid operation specified."}, 400
except Exception as e:
print(f"Error occurred: {e}")
return {"error": str(e)}, 500이렇게 설계했음.
깔끔하게 테스트 시작과 끝을 하기 위해서 테이블 생성 드랍으로 마무리하고.
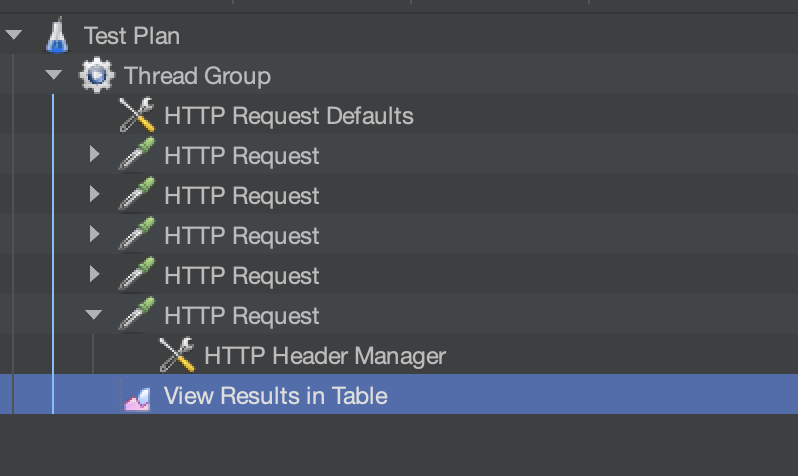
여기서 하나의 메서드에 순차적으로 요청을 보내서 CRUD를 하는 식임.
지금 보니까 실패를 너무 많이하는데 엔드포인트가 하나라 병목현상을 해결하지 못하는 것 같다.
엔드포인트 하나로 해결하려고 했는데 결과를 보니 전제 자체를 잘못한듯.
이러면 엔드포인트 CRUD를 다 나누어서 해야될 것 같다.
아! 그리고 테스트에 drop 메서드를 포함시켜서 오류가 엄청나게 났음.
생각해보니까 테스트 중간에 계속 drop이 시도되면 없을 때 요청도 보내지니까 오류률이 겁나게 올라감. 이건 테스트에 포함시키지 말고 postman으로 따로 요청보내서 정리하면 됨.
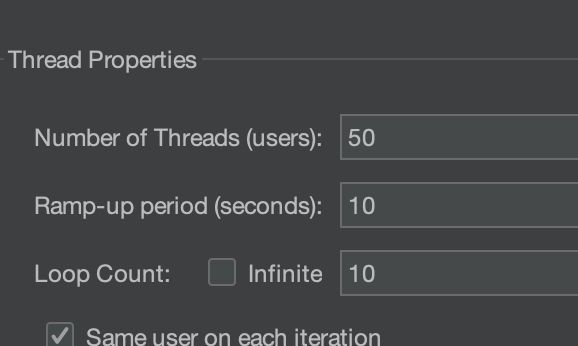
그래서 이렇게 보내본 결과
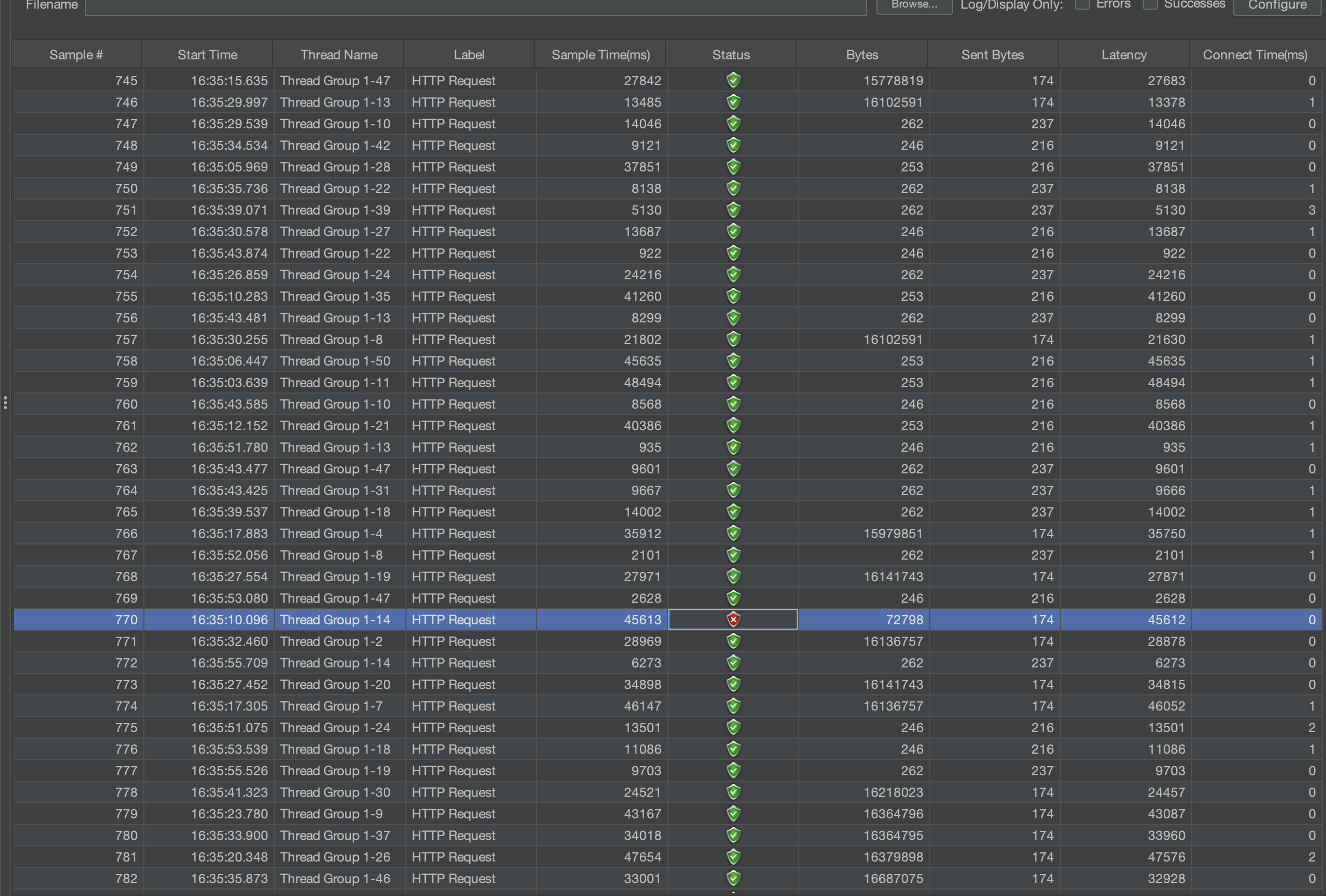
오류가 몇개 보이긴 했는데 거의 보이지 않았고 이정도 오류면 이것 또한 테스트의 일환이라고 생각함. 이제 이 결과를 파일로 저장하고 다음 MariaDB 테스트 진행해보면 될듯함.
해놓고 레슨하러 간다고 노트북을 닫아서 조금 오래 걸릴 것 같긴한데 지금 짬나는 시간에 확인해보니까 다 됐음.
그럼 이제 파일 추출해보자.

파일 두개 얻었고 이제 이걸로 새 프로젝트 열어서 그래프로 그려보자.
새 프로젝트 생성했고,
pip install matplotlib pandas그래프를 그리는데 필요한 라이브러리 다운 받아줌.
코드 짜고..
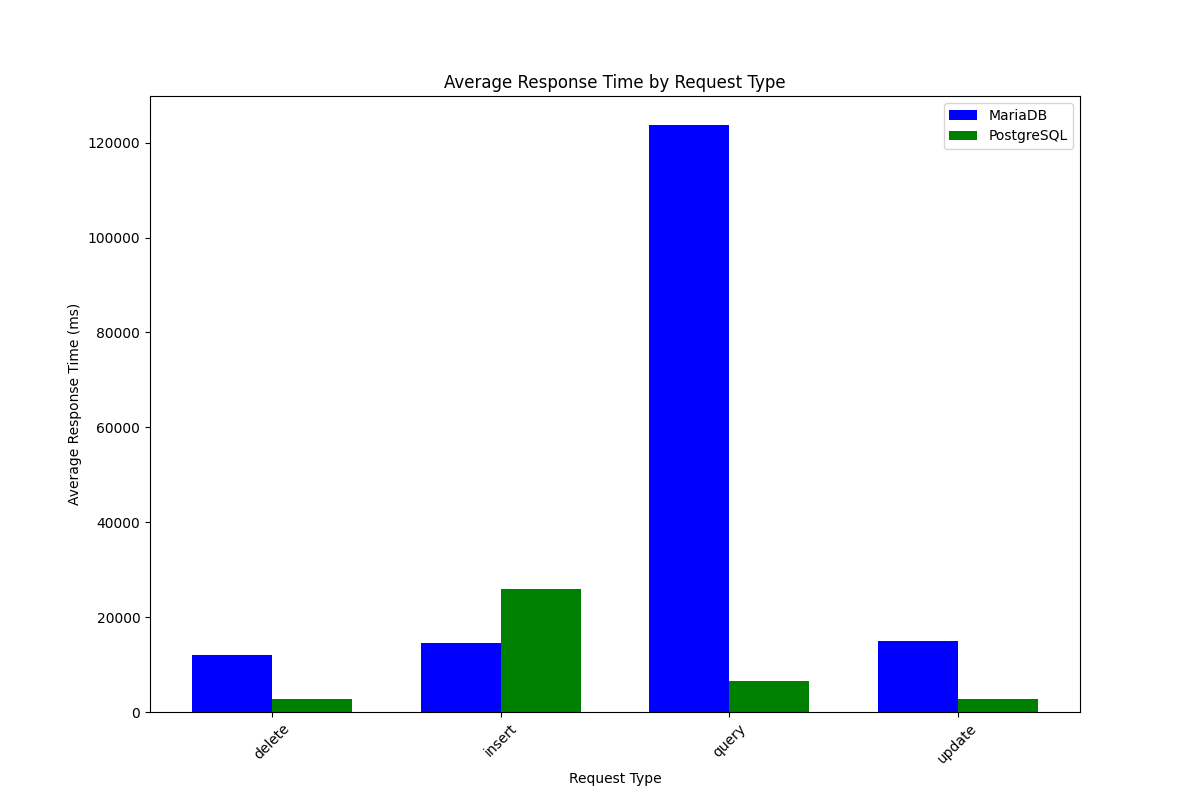
결과임.
읽기에서 포스트그릴이 크게 효율적인 모습을 보여줬음.
{kind=link}
결론.
원래 같았으면 DB를 바꾸는 작업을 했을 것 같은데 이건
db_engine = create_engine(
app.config['SQLALCHEMY_DATABASE_URI'],
pool_size=10, # 기본 연결 수
max_overflow=20, # 최대 초과 연결 수
pool_timeout=30,
pool_pre_ping=True # 끊어진 연결 확인
)내가 이걸 너무 작게 줬던게 원인일터. 아마 넓혀주면 바로 해결 되는 문제일거임.
# SQLAlchemy 엔진 최적화 설정
db_engine = create_engine(
app.config['SQLALCHEMY_DATABASE_URI'],
pool_size=50, # 기본 연결 수
max_overflow=100, # 최대 초과 연결 수
pool_timeout=60,
pool_pre_ping=True # 끊어진 연결 확인
)그래서 넓혀줌.. 재배포까지는.. 언젠가 하겠다.
여튼 이렇게 결론남.
기본 설정을 해줄 때 이 역할이 내가 데이터의 흐름과 규모를 생각하고 설정을 해줬어야함. 이걸 빼먹고 그냥 통상적으로 쓰는 설정을 가져와서 문제가 됐던 것.
공부가 되었다.
'Coding History' 카테고리의 다른 글
| 내 소개 사이트 제작중 생긴 문제 해결.nginx 도메인 설정, https 적용 후 재배포 (1) | 2024.12.20 |
|---|---|
| AWS 자동 배포 (1) | 2024.11.14 |
| AWS 서버 구성, 도메인 연결. (1) | 2024.11.13 |
| 서버 DB 영속성 부여 -> 그냥 연습용 예제 (0) | 2024.11.11 |
| git hub action (CI / CD) (1) | 2024.11.07 |