행성 데이터를 좀 잘 만들었으니까 별자리 데이터도 좀 더 수정하고 싶었다.
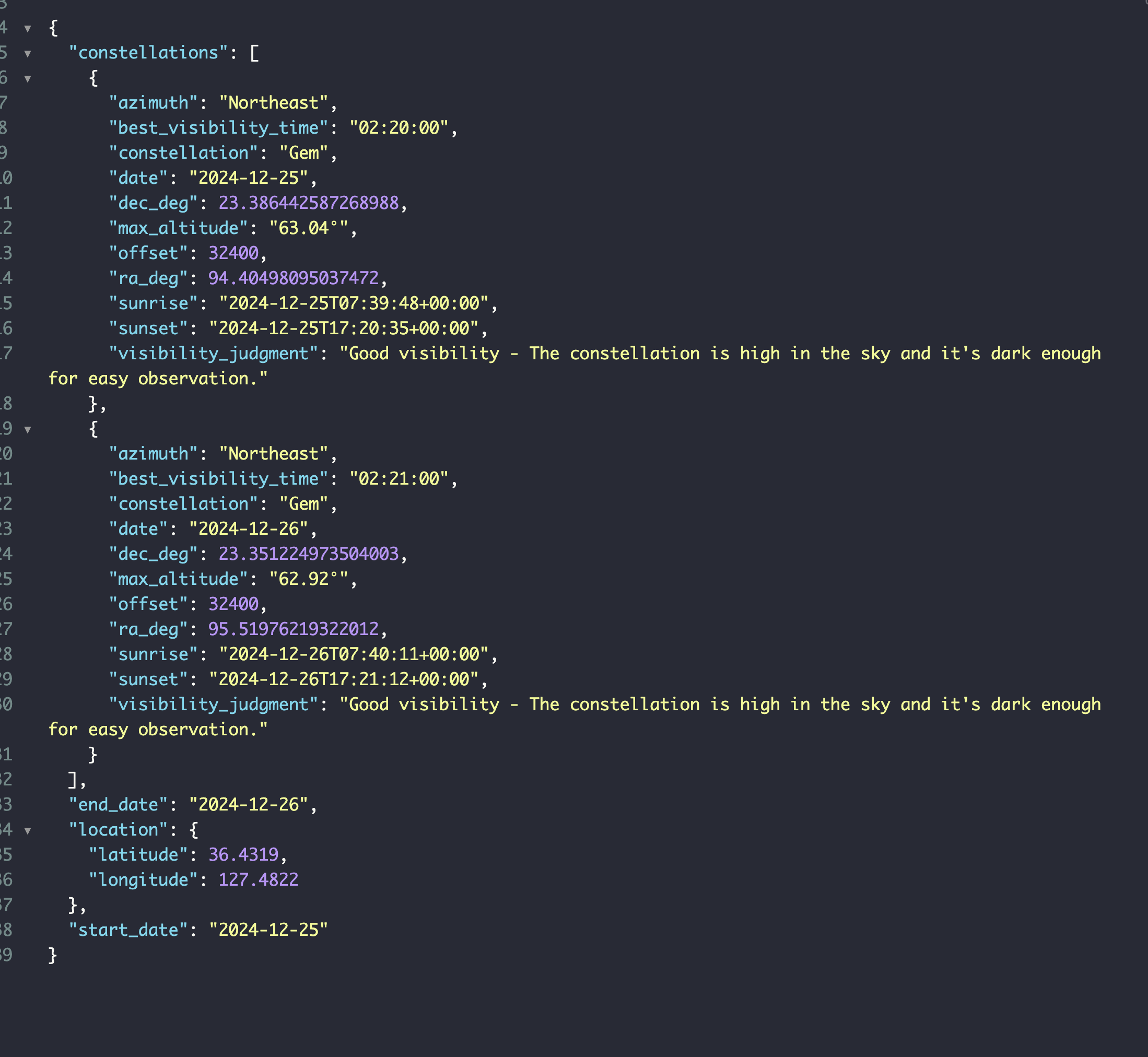
결과부터 보면 이렇게 표기되게끔 바꿨다.
대충 뭘 했냐면 관측자가 바라보는 곳을 애매하게 지정해서 계산중이였는데 constellation_service에서 가져온 별자리 이름과 적경과 적위를 사용해서 계산하게끔 하고 관측자의 시선도 해당 별자리로 고정시켜서 계산하게끔 바꾸었다.
방위에 대한 설정도 해주었다.
근데 계산 로직이 좀 많아져서 그런가 데이터를 반환하는데 시간이 조금 오래 걸렸다.
이것도 DB에...? ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 일단은 시간을 줄일 방법을 찾아보자.
multiprocessing.Pool
찾아보니까 이런게 있네. 계산을 병렬처리 한다고 한다.
원래는 별자리를 찾는 로직과, 해당 데이터로 계산하는 로직 두개였는데, 계산쪽에서 너무 많은걸 계산해서 늦어진다. 또 별자리를 화면에 띄워줄걸 생각하면 한달씩 요청하게 될 것 같은데, 날짜가 많아질수록 오래걸렸다.
그래서 지금 병렬처리가 아주 좋은 선택이 될 것 같아서 적용해봤다.
수정후 별자리 로직은 메서드가 총 세개로 작동하고 있는데,
별차리를 찾는 메서드(get_constellations_for_date_range) 특정 날짜와 위치에서 가장 잘 보이는 시간대를 계산하는 개별 처리 메서드(process_day_data) 여러 날짜에 대한 별자리 가시성 정보를 병렬로 계산하는 메서드 (calculate_visibility_for_constellations_parallel) 이렇게 해서 multiprocessing.Pool을 적용을 했다.
음.. 드라마틱한 효과는 없는 것 같다.
그래도 제대로 작동은 한다.
생각해보니까 어차피 잘보일 별자리를 미리 뽑아서 보여주는건데 visibility_judgment가 필요할까? 조건문빡빡하게 해놨는데, 어차피 보일 데이터를 계산하는데 좀 과한 욕심이 있었던 것 같다.
삭제 완료.
좀 고민을 오래하다가 이런 것들이 있어서 죄다 적용했다..
- Skyfield의 벡터화: 여러 시점의 천체 위치 계산을 한 번에 수행하여 성능을 개선.
- Lazy Evaluation: 고도가 모두 음수인 경우 빠르게 결과를 반환해 불필요한 계산을 줄이기.
- 데이터 필터링: 최고 고도가 낮아 관측이 어려운 경우 미리 판단하여 결과를 반환.
- 프록시 값 캐싱 (
lru_cache): 동일한 별자리 가시성 요청에 대해 중복 계산을 피하도록 캐싱을 적용.- 프록시 값은 실 사용할 때 효과가 있음.
이렇게 하니까 미약하게나마 빨라졌다.
결과는
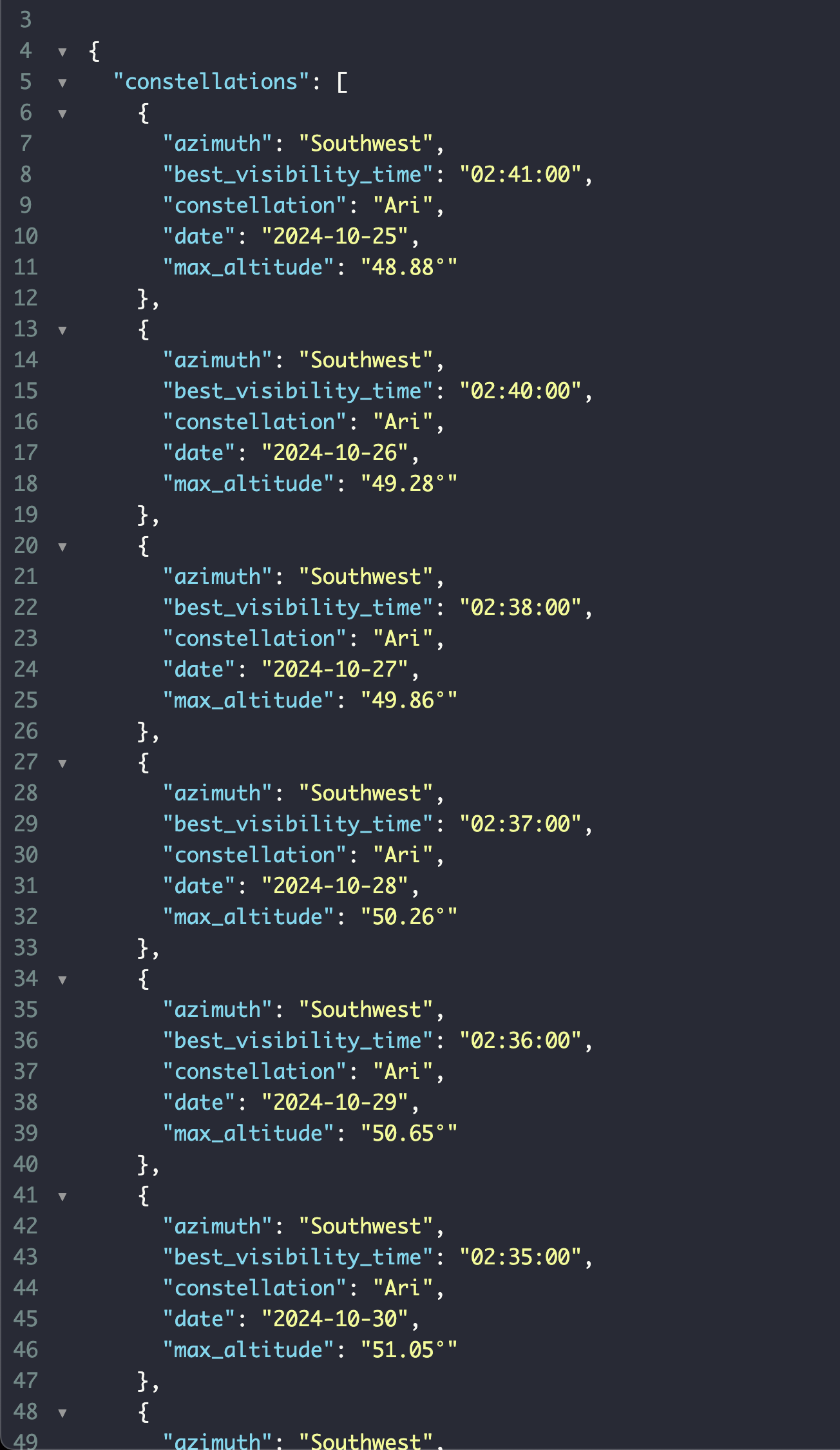
더이상 빨라지게는 못할 것 같으니까 여기까지.
'Coding History > Team Project' 카테고리의 다른 글
| 팀플) 혜성 예측 로직 구상. (0) | 2024.10.19 |
|---|---|
| 팀플) 혜성 이벤트 시작! (데이터 접근, 파싱, 추출) (2) | 2024.10.19 |
| 팀플) 행성의 가시성 -> DB 생성 로직 삭제, DB 조회만. (가시성 판단 로직 정교화) (5) | 2024.10.18 |
| 팀플) 대행성 로직 간단화와 행성별로 나누기 (0) | 2024.10.18 |
| 팀플) 행성 대접근 로직 수정. (LIST 반환.. xxx 데이터 간략화 하기, 행성별로 나누자는 생각 도달.) (0) | 2024.10.18 |