이젠 혜성 이벤트로직을 만들면 된다. 해당 정보도 이제 호라이즌 API 에서 반환 받고, 계산을 하면 된다.
우선은 행성에 대한 로직을 짤 때 사용했던 파일에서 혜성에 대한 정보를 가져오기로 헀다.
COMET_CODES = {
"Halley": "1P",
"Encke": "2P",
"Biela": "3P"
}
def get_comet_approach_events(comet_name, date, range_days):
comet_code = COMET_CODES.get(comet_name)
if not comet_code:
return {"error": "Invalid comet name."}
# 포맷 전 로그
# print(f"Formatted Date Before: {date}")
if isinstance(date, float):
date = datetime.fromtimestamp(date) # float를 datetime으로 변환
# 포맷 후 로그
# print(f"Formatted Date After: {date}")
# 단일 날짜 요청 처리
if range_days == 1:
end_date = date + timedelta(days=1)
else:
end_date = date + timedelta(days=range_days)
url = "https://ssd.jpl.nasa.gov/api/horizons.api"
params = {
"format": "json",
"COMMAND": f"'{comet_code}'",
"CENTER": "'500@399'", # 지오센터 기준
"MAKE_EPHEM": "YES",
"EPHEM_TYPE": "OBSERVER",
"OBJ_DATA": "YES",
"START_TIME": f"'{date.strftime('%Y-%m-%d')}'",
"STOP_TIME": f"'{end_date.strftime('%Y-%m-%d')}'",
"STEP_SIZE": "'1 d'",
"QUANTITIES": "'1,20,23'" # 필요한 데이터만 요청 (시간, 적경/적위, 태양 거리)
}
response = requests.get(url, params=params)
print(f"Request URL: {response.url}") # 요청 URL 로그
print(f"Response Status Code: {response.status_code}") # 응답 상태 코드 로그
if response.status_code == 200:
try:
data = response.json()
# print(f"Response Data: {data}") # 응답 데이터 로그
if 'result' in data:
# 파싱 로직 추가
result_lines = data['result'].splitlines()
parsed_data = []
extracting = False
for line in result_lines:
if "$SOE" in line:
extracting = True
continue
elif "$EOE" in line:
extracting = False
break
if extracting:
parsed_data.append(line)
# print(f"Parsed Data: {parsed_data}") # 파싱된 데이터 로그
# 파싱된 데이터를 딕셔너리 형태로 변환
parsed_dict = []
for entry in parsed_data:
parts = entry.split()
parsed_dict.append({
"time": f"{parts[0]} {parts[1]}",
"ra": f"{parts[2]} {parts[3]} {parts[4]}",
"dec": f"{parts[5]} {parts[6]} {parts[7]}",
"delta": parts[8],
"s-o-t": parts[10]
})
# print(f"Parsed Dictionary: {parsed_dict}") # 딕셔너리 형태의 파싱 데이터 로그
return {"data": parsed_dict}
else:
return {"error": "Unexpected response format from Horizons API."}
except ValueError as e:
print(f"JSON parsing error: {e}") # JSON 파싱 에러 로그
return {"error": "Failed to parse JSON response from Horizons API."}
else:
return {"error": f"Failed to retrieve data from Horizons API. Status code: {response.status_code}"}
어떤 데이터가 넘어올지는 모르지만 일단은 그래도 가져와서 (어차피 url이 요청시에 남아서 그걸 타고 어떤 데이턴지 확인하려고) 간단하게 만들어보자.
# services/comet_approach_service.py
from app.services.horizons_service import get_comet_approach_events
from datetime import datetime
def get_comet_approach_data(comet_name, start_date, range_days=30):
"""
주어진 혜성의 접근 이벤트 데이터를 반환하는 함수.
Args:
comet_name (str): 혜성 이름 (예: "Halley", "Encke", "Biela").
start_date (str): 검색 시작 날짜 (형식: 'YYYY-MM-DD').
range_days (int, optional): 검색할 범위 일수. 기본값은 30일.
Returns:
dict: 혜성 접근 이벤트 데이터 또는 오류 메시지.
"""
try:
# 날짜 문자열을 datetime 객체로 변환
start_date_obj = datetime.strptime(start_date, '%Y-%m-%d')
# Horizons API를 호출하여 혜성 접근 이벤트 데이터를 가져옴
return get_comet_approach_events(comet_name, start_date_obj, range_days)
except Exception as e:
return {"error": f"Failed to get comet approach data: {str(e)}"}여기서 이제 혜성 접근 이벤트를 계산할 메서드도 일단은 데이터만 넘겨받게 만들어주고 루트에 엔드포인트까지 작성했다.
바로 뭔가 넘어오면 좋겠지만 두번만에 요청에 성공했으니, 그것만으로도 감사하다.

이걸 타고 넘어가면

데이터를 확인할 수 있다.
요청 url은 대충 알았으니 이제 코드를 고치기보다는 요청을 계속 고치면서 원하는 데이터가 나올 때 까지 탐색해봐야한다.
일단 지금 반환 받은 결과를 좀 살펴보면
기록 90000001 부터 90000030까지 요청해보라고 하는 것 같다. 그래서
COMMAND=%2790000001커맨드를 1P가 아닌 해당 레코드로 바꿔서 요청해보았고.

음.. 결과 같은 결과가 나왔다.
내가 혼자 이걸 까서 해석하면 아마 하루종일 안걸릴까? GPT 시켜야지 ㅋㅋ
결과 데이터 해석
- Comet Physical Information:
- 반지름 (RAD): 5.5 km
- 질량 관련 매개변수 (
M1,M2), 밝기 상수 (k1,k2) 등의 물리적 정보가 포함되어 있음.
- 천문요소 정보:
- EPOCH: 혜성의 천문요소가 적용된 기준 시간 (예:
239-Jun-07.0000000) - 궤도 요소 (이심률, 근일점 거리, 경도, 경사도 등)가 포함되어 있어 혜성의 궤도를 분석하는 데 사용된다.
- EPOCH: 혜성의 천문요소가 적용된 기준 시간 (예:
- 에페메리스 데이터 (
Ephemeris):- 날짜별로 적경(R.A.)과 적위(DEC), 태양 거리(delta) 등 위치 정보가 제공된다.
S-O-T값은 태양, 관찰자, 대상 천체 간의 각도 정보를 포함한다.
- 관찰 조건:
- 혜성의 태양-관찰자-대상 각도, 달과의 거리, 조명율 등의 정보도 제공되며, 이는 관측 가능성을 판단하는 데 유용하다.
라고 하네요.
그럼 이걸 혜성 이벤트 정보를 계산해 내는데 합당한 데이터인가를 일단 알아야된다.
물어보니까 계산할 수 있다고 하는구만.
난 잘 모르겠다. 뭔가 행성은 그래도 약간은 길이 보였는데 이건 진짜 안보이네.. 그래도 뭐 하다 보면 되겠지
오... 방금 안 사실인데 지금 요청한 90000001번은 기원전 -239년도 데이터라고 한다. 진짜 실화냐?
그리고 마지막 번호인 90000030번은 1968년도 데이터라고 한다. 이걸로 계산이 가능한가?
암튼 다음 혜성인 2P/Encke도 한번 까봤는데
얘는 주기가 짧아서 그런지 2022년에 업데이트 된 기록이 있다. 90000091번 데이터다.
3P는 검색해보니까 인덱스가 없다고 떠서 알아보니까 Biela라는 혜성인데 두조각으로 나뉘면서 소멸했다고 한다. 그래서 없는듯..
4P, 5P... 해서 좀 다 봤는데 의외로 최신 데이터다. 첫 빠따가 이상한거였네 쟤는 왜 더 관측안하지?
우선은 혜성을 리스트업할 필요가 있어보여서 공식 문서로 규칙을 알아냈다.
P가 붙는 애들은 주기성을 갖는 혜성. D가 붙는 애들은 소멸하거나 불안정한 혜성. (3D로 검색하니까 나오더라..) C로 붙는 애들은 비주기 혜성.
이정도로 나뉘어서 P로 붙는 주기 혜성들을 리스트업해서 보여달라고 GPT한테 부탁했다.
P가 붙는 주기 혜성 리스트
주기 혜성 목록
- 1P/Halley - 할리 혜성 (주기: 약 76년)
- 2P/Encke - 엔케 혜성 (주기: 약 3.3년)
- 4P/Faye - 파예 혜성 (주기: 약 7.5년)
- 5D/Brorsen - 브로르센 혜성 (소멸된 것으로 여겨짐)
- 6P/d'Arrest - 다레스트 혜성 (주기: 약 6.6년)
- 7P/Pons-Winnecke - 폰스-윈네케 혜성 (주기: 약 6.3년)
- 8P/Tuttle - 터틀 혜성 (주기: 약 13.5년)
- 9P/Tempel 1 - 템플 1 혜성 (주기: 약 5.5년)
- 10P/Tempel 2 - 템플 2 혜성 (주기: 약 5.4년)
- 11P/Tempel-Swift-LINEAR - 템플-스위프트-LINEAR 혜성 (주기: 약 6.4년)
- 13P/Olbers - 올버스 혜성 (주기: 약 69.5년)
- 14P/Wolf - 울프 혜성 (주기: 약 8.8년)
- 19P/Borrelly - 보렐리 혜성 (주기: 약 6.8년)
- 21P/Giacobini-Zinner - 자코비니-진너 혜성 (주기: 약 6.6년)
- 22P/Kopff - 콥프 혜성 (주기: 약 6.4년)
- 26P/Grigg-Skjellerup - 그리그-셰를럽 혜성 (주기: 약 5.1년)
- 27P/Crommelin - 크롬멜린 혜성 (주기: 약 27.4년)
- 28P/Neujmin 1 - 누이민 1 혜성 (주기: 약 18.2년)
- 45P/Honda-Mrkos-Pajdusakova - 혼다-므르코스-파이두사코바 혜성 (주기: 약 5.3년)
- 55P/Tempel-Tuttle - 템플-터틀 혜성 (주기: 약 33.2년, 레오니드 유성우의 원인)
- 67P/Churyumov-Gerasimenko - 추류모프-게라시멘코 혜성 (주기: 약 6.5년, 로제타 탐사선으로 유명)
- 73P/Schwassmann-Wachmann 3 - 슈바스만-바흐만 3 혜성 (주기: 약 5.4년)
- 75P/Kohoutek - 코후테크 혜성 (주기: 약 6.4년)
- 81P/Wild 2 - 와일드 2 혜성 (주기: 약 6.4년)
- 89P/Russell 2 - 러셀 2 혜성 (주기: 약 7.6년)
- 103P/Hartley 2 - 하틀리 2 혜성 (주기: 약 6.5년)
- 109P/Swift-Tuttle - 스위프트-터틀 혜성 (주기: 약 133년, 페르세우스 유성우의 원인)
- 126P/IRAS - IRAS 혜성 (주기: 약 13.6년)
- 141P/Machholz 2 - 마흐홀츠 2 혜성 (주기: 약 5.2년)
- 153P/Ikeya-Zhang - 이케야-장 혜성 (주기: 약 366.5년)
오 이렇게 보니까 유성우도 예측이 되긴하겠는데?
여튼 주기가 짧은 애들 위주로 검색하고 데이터 검증을 시도해보는게 좋을 것 같다.
다 뽑아봤으니까. 이걸 어떻게 파싱하고 나열할지. 그리고 지금 보면 요청을 두번 거치지 않으면 데이터를 가져올 수가 없는 형태라서 어떻게 가져올 것인지 고민을 좀 해봐야한다. 이거 좀 어려울 것 같다.
이것도 그리고 이것도 데이터 꼬라지 보니까 DB 저장 해야될 것 같다..
일단 왜 두번 요청을 해야되냐면
지금 나도 두번씩 요청을 하면서 찾고 있는데 이게 문서화 되어있지 않다. 아마도 얘네가 업데이트를 하게 되면 그걸 요청해보고 알아서 알아먹으라고 그런 것 같기도 하고 이유는 모르겠다.
여튼 왜 두번 요청이냐?
첫 번째 요청은 특정 혜성에 대한 '레코드 번호'를 찾기 위한 검색 요청이고,
두 번째 요청은 해당 레코드 번호를 사용하여 해당 혜성의 궤도 데이터와 접근 이벤트 데이터를 얻기 위한 요청이다.
그래서 필연적으로 두번 요청을 해야한다.
일단은 내 api로 요청시에 내가 사용할 데이터를 올바르게 뽑아 오는걸 목표로 하고, 이후에 스케줄러를 사용해 DB에 저장하는식으로 가야될 것 같다.
그래서 두번 요청을 위해서 메서드를 나누었다.
get_comet_record_number로 record-number를 넘겨 받을 것이고, get_comet_approach_events에서 내가 원하는 정보를 뽑아올 생각이다.
get_comet_approach_events가 실행할 때, record_number = get_comet_record_number(comet_name) 메서드를 불러오면서 record-number를 추출.. 그리고 유효한 url 작성.. 이런 식이다.
여튼 내가 이벤트 계산에 필요한 데이터는 1,2,20,23,25번이기 때문에
{
1: 시간
2: 태양 거리
20: 적경 (RA)
23: 적위 (DEC)
25: 속도 (deldot)
}"QUANTITIES": "'1,2,20,23,25'" 이렇게 설정도 해줬고..
그리고 코드를 작성하면서 드는 생각인데, 이것마저 사용자에게 날짜를 세세하게 요청받을 필요가 있을까? 였다.
왜?
생각해보면 혜성의 주기야말로 겁나 길다. 그럼 만약 사용자가 30일치의 데이터를 요청한다고 하면 우리는 계산을 30일치만 해서 줘야하는데 위에 보이다 시피 겁나 길어서 정확하지 않을 확률이 굉장히 높아진다. 그러니까 이것도 무조건 DB에 저장해놓고 써야한다.
왜?!?!?!
만약 우리가 1년치를 미리 저장해 놓고 그걸 토대로 계산도 해 놓고 사용자에게 갖다 주면 사용자는 그냥 혜성 정보를 요청만 하면 DB에 있는걸 꺼내주면 끝이다. 1년치 데이터를 미리 계산해서 저장해 뒀으니 정확도면에서도 조금 더 정확할 확률이 높고, 무엇보다 지금 꼴을 보면 계산도 굉장히 복잡해질텐데 사용자 경험 면에서도 DB에서 결과값을 바로 내어주는게 편할 것이다..
지금 주기 혜성 목록에서 기간이 너무 긴 것들은 빼고(유성우는 남기자.) 사라진 것도 빼고 최대한 DB에 많이 안들어가게 설정해둬야겠다.
뭐 우선 요청부터 성공한다면 말이지.
여튼 로직은 대충 짰고 이제 해보면 된다.
짠 로직을 한번씩 요청하면서 일단 레코드 번호가 나오기를 기대하고 있다..

한번만 더 앞으로 가면 된다 ㅋㅋㅋㅋ
근데 하면서 느낀게 이러면 첫번째 레코드 번호를 가져오는거 아닌가? 였다. 그럼 우리는 로직 계산을 할 때, 기원전 데이터를 사용하게 되는데? 하.. 이거 진짜 쉽지 않네.
그래서 여튼 최신 레코드를 가져오려면 어떻게 해야될까
GPT가 제안한게 모든 레코드 번호 검사 후 최신 레코드 찾기, 정렬 후 최신 레코드 선택이였는데, 어차피 여기서 요청한 데이터 또한 DB에 저장할 계획이기 때문에 오래걸려도 상관없으니 더 구현하기 쉬운놈으로 하자.

음 짜본 코드가 잘못됐나보다. 다시.
다시 해보려다가 문든 든 생각이 텍스트 형식으로 받으면 더 파싱하기 쉬울 것 같았다.
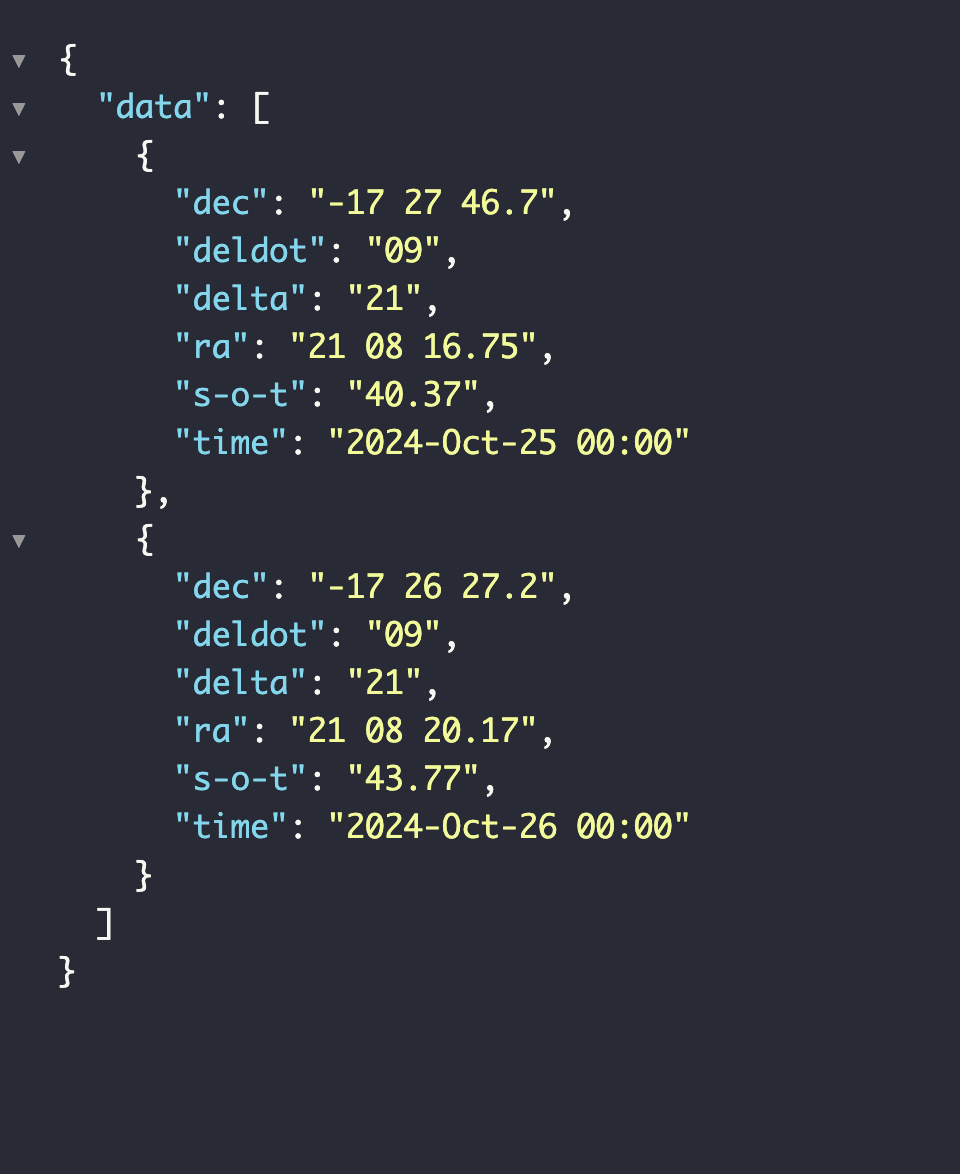
우선 사진을 보자
Json 반환
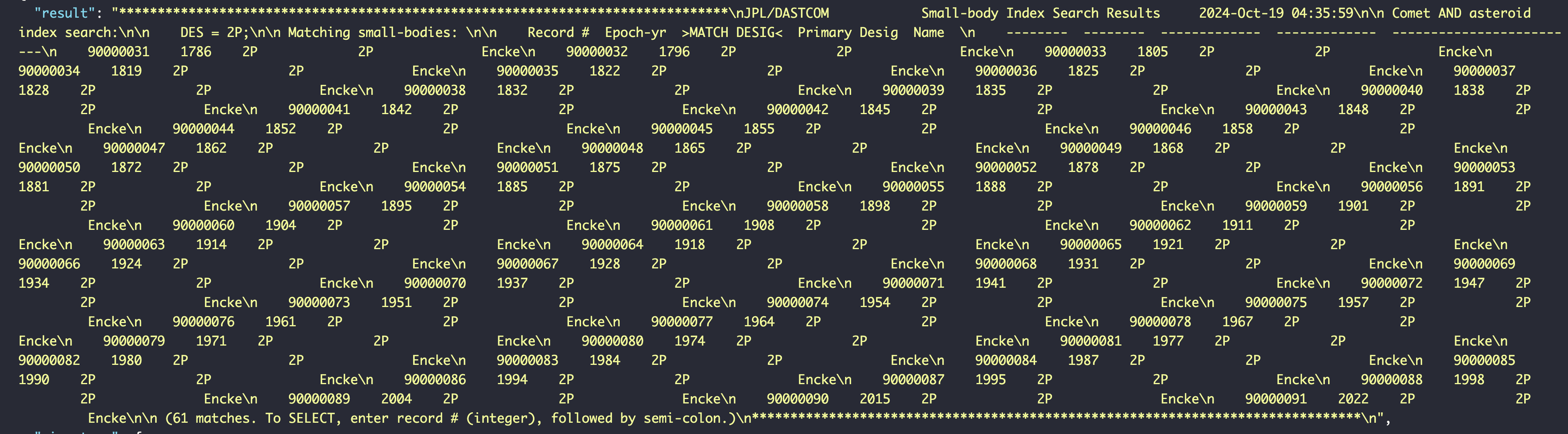
딱 봐도 좀 복잡해보인다.
TEXT 반환
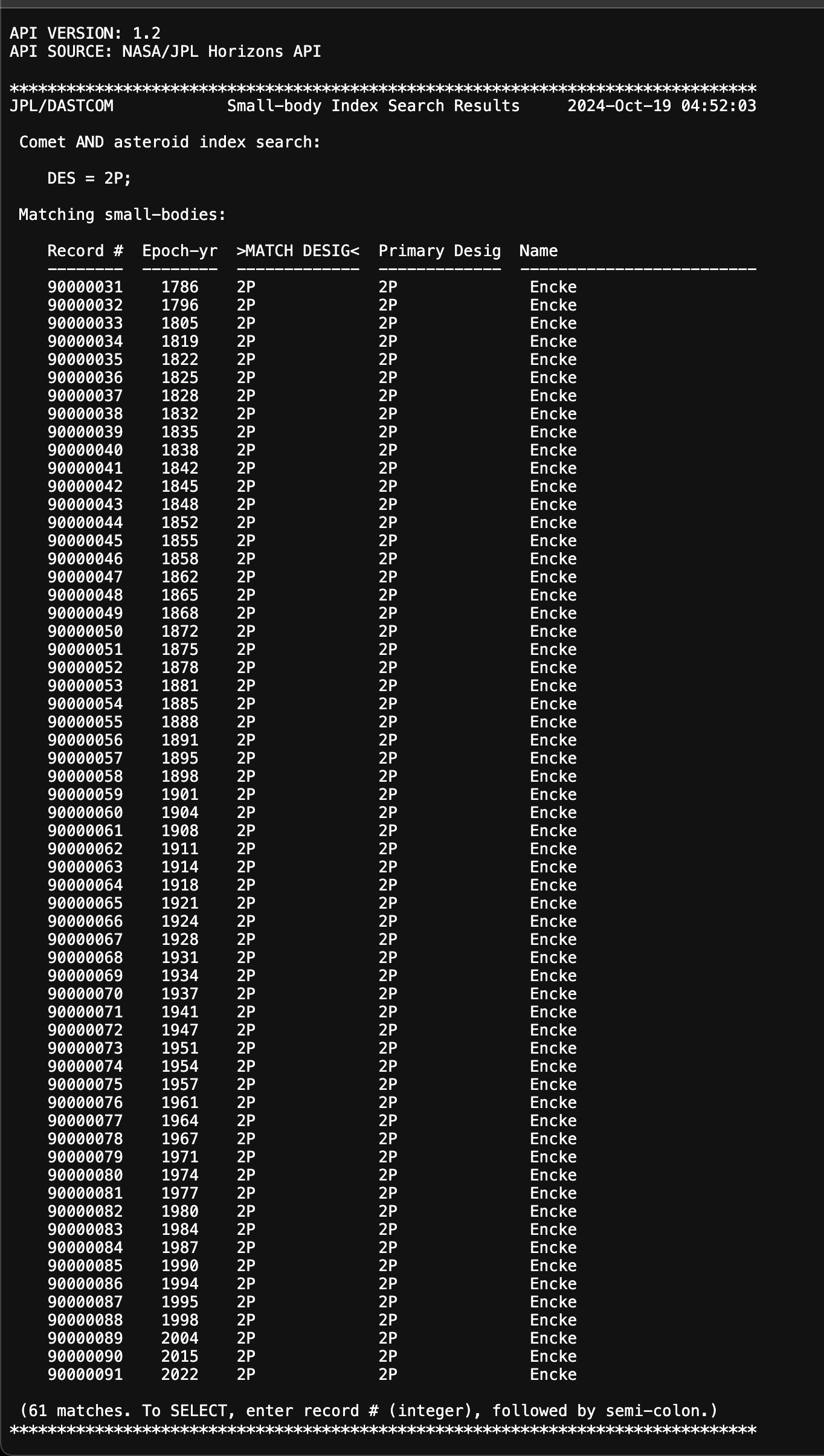
좀 더 직관적이지 않은가? 이걸 이제 줄로 나눠서 리스트로 묶어서 해버리면 좀 편하지 않을까?
def get_comet_latest_record_number(comet_name):
comet_code = COMET_CODES.get(comet_name)
if not comet_code:
return {"error": "Invalid comet name."}
url = "https://ssd.jpl.nasa.gov/api/horizons.api"
params = {
"format": "text", # 텍스트 형식으로 요청
"COMMAND": f"'{comet_code}'",
"OBJ_DATA": "NO"
}
response = requests.get(url, params=params)
print(f"Request record-Num URL: {response.url}")
print(f"Response Status Code: {response.status_code}")
if response.status_code == 200:
try:
data = response.text # 텍스트로 결과를 받음
result_lines = data.splitlines()
latest_record = None
latest_year = float('-inf')
for line in result_lines:
if "Record #" in line:
parts = line.split()
if len(parts) > 2:
record_number = parts[0]
try:
epoch_year = int(parts[1])
# 최신 연도를 가진 레코드 선택
if epoch_year > latest_year:
latest_year = epoch_year
latest_record = record_number
except ValueError:
continue
if latest_record:
print(f"Extracted Latest Record Number: {latest_record}")
return latest_record
else:
return {"error": "Failed to extract the latest record number."}
except Exception as e:
print(f"Parsing error: {e}")
return {"error": "Failed to parse response from Horizons API."}
else:
return {"error": f"Failed to retrieve data from Horizons API. Status code: {response.status_code}"}그래서 텍스트로 받아보기로 결정.
우선 안돼서 어떻게 나오는지 보기 위해서 line별로 로그를 찍었다.
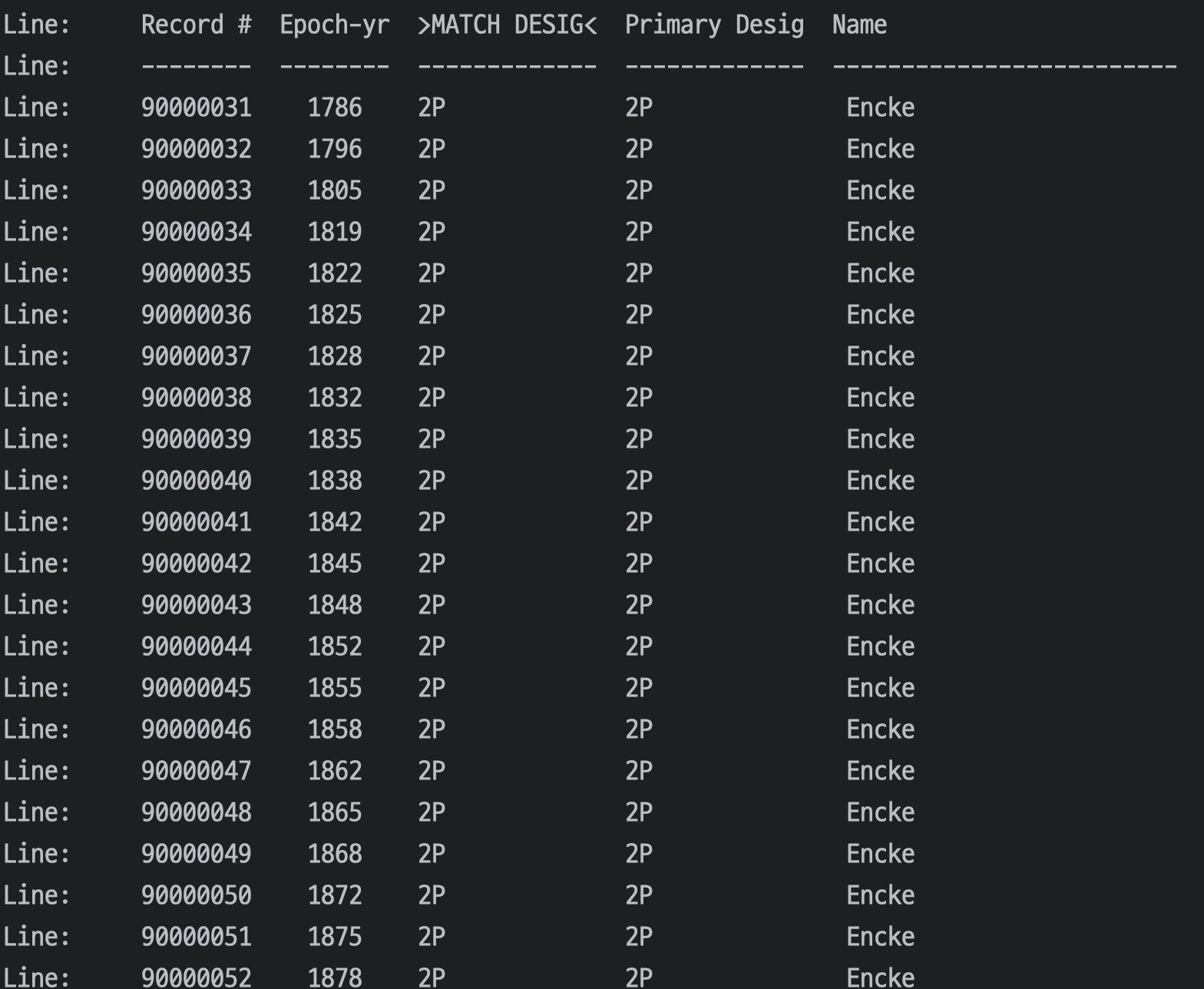
로그 찍고 조건을 더 빡빡하게 걸어줬는데
밑의 로직까지 한번에 성공해버렸다..ㅋㅋㅋㅋㅋ

제일 최신 것으로 파싱해서 가져온 것 까지 확인.
제일 밑은 이미 행성 로직이 있어서 그거 갖다 쓴거라 운 좋게 바로 된 것 같다.
그럼 오늘은 여기까지. 내일은 DB에 로우데이터로 저장할 거 만들어야겠?다? 몰?루
'Coding History > Team Project' 카테고리의 다른 글
| 팀플) 혜성 로직 짜기. (1) | 2024.10.21 |
|---|---|
| 팀플) 혜성 예측 로직 구상. (0) | 2024.10.19 |
| 팀플) 별자리 데이터 수정. (0) | 2024.10.19 |
| 팀플) 행성의 가시성 -> DB 생성 로직 삭제, DB 조회만. (가시성 판단 로직 정교화) (5) | 2024.10.18 |
| 팀플) 대행성 로직 간단화와 행성별로 나누기 (0) | 2024.10.18 |