이제는 유성우 데이터 DB 저장과 조회가 될 수 있게 만들면 된다.
지금까지 만들어둔 로직은 이제 로우데이터를 생성만 하는 것이고. 메서드를 분리해서 자동으로 로우데이터를 저장하게끔 설계할 생각이다.
# services/comets/meteor_shower_info_storage_service.py
from apscheduler.schedulers.background import BackgroundScheduler
from datetime import datetime
from app.models.meteor_shower_raw_data import MeteorShowerInfo
from app.services.comets.meteor_shower_info import get_meteor_shower_info
from app import db
import atexit
from app.data.data import METEOR_SHOWERS
def save_meteor_shower_info(shower_info):
"""
유성우 정보를 데이터베이스에 저장하는 함수.
Args:
shower_info (dict): 저장할 유성우 정보.
"""
peak_period_str = ', '.join(shower_info["peak_period"]) if isinstance(shower_info["peak_period"], list) else \
shower_info["peak_period"]
meteor_shower_record = MeteorShowerInfo(
comet_name=shower_info["comet_name"],
name=shower_info["name"],
peak_period=peak_period_str,
peak_start_date=shower_info["peak_start_date"],
peak_end_date=shower_info["peak_end_date"],
message=shower_info["message"],
conditions_used=shower_info["conditions_used"],
status=shower_info["status"],
distance=shower_info["distance"],
ra=shower_info["ra"],
declination=shower_info["declination"]
)
db.session.add(meteor_shower_record)
db.session.commit()
def update_meteor_shower_data():
"""
앞으로 3년간의 유성우 데이터를 모든 혜성에 대해 저장하는 함수.
"""
comet_names = ["Halley", "Encke", "Swift-Tuttle", "Tempel-Tuttle"]
current_year = datetime.now().year
start_date = f"{current_year}-01-01"
range_days = 365 * 3 # 3년간의 데이터를 저장하기 위한 일수
for comet_name in comet_names:
# `METEOR_SHOWERS`에 유성우 정보가 있는지 확인
if comet_name not in METEOR_SHOWERS:
print(f"No meteor shower data available for comet: {comet_name}")
continue # 유성우 정보가 없는 혜성은 건너뛰기
# 유성우 정보 가져오기
shower_info_list = get_meteor_shower_info(comet_name, start_date, range_days)
if isinstance(shower_info_list, list):
for shower_info in shower_info_list:
# 중복 데이터 확인 후 저장
existing_info = db.session.query(MeteorShowerInfo).filter(
MeteorShowerInfo.comet_name == shower_info["comet_name"],
MeteorShowerInfo.peak_start_date == datetime.strptime(shower_info["peak_start_date"],
'%Y-%m-%d').date()
).first()
if not existing_info:
save_meteor_shower_info(shower_info)
else:
error_message = shower_info_list.get('error', "Unknown error")
print(f"Error updating data for {comet_name}: {error_message}")
raise Exception(f"Error updating data for {comet_name}: {error_message}")
# 스케줄러 설정
scheduler = BackgroundScheduler()
# 3년마다 1월 1일 자정에 유성우 데이터를 업데이트하는 작업 추가
scheduler.add_job(update_meteor_shower_data, 'cron', year='*/3', month='1', day='1', hour='0', minute='0')
scheduler.start()
# 앱이 종료될 때 스케줄러도 같이 종료되도록 설정
atexit.register(lambda: scheduler.shutdown())
def get_stored_meteor_shower_info(comet_name, year=None):
"""
저장된 유성우 정보를 반환하는 함수.
Args:
comet_name (str): 혜성의 이름.
year (int, optional): 검색할 연도. None이면 모든 연도의 정보를 가져옴.
Returns:
list: 유성우 정보 리스트.
"""
try:
query = db.session.query(MeteorShowerInfo).filter(MeteorShowerInfo.comet_name == comet_name)
if year:
query = query.filter(MeteorShowerInfo.peak_start_date.between(f"{year}-01-01", f"{year}-12-31"))
results = query.all()
if not results:
return {"error": "No meteor shower info found for the specified comet."}
return [
{
"name": row.name,
"peak_period": row.peak_period,
"peak_start_date": row.peak_start_date.isoformat(),
"peak_end_date": row.peak_end_date.isoformat(),
"message": row.message,
"conditions_used": row.conditions_used,
"status": row.status,
"distance": row.distance,
"ra": row.ra,
"declination": row.declination
}
for row in results
]
except Exception as e:
return {"error": f"Database operation failed: {e}"}우선 성공 시켰고 그렇게 큰 문제는 있지 않았다. 문제가 있다면 난 3년치를 넣고 싶은데 1년만들어간거..? 그래서 의도대로 코드가 작동하지 않아서 손을 좀 봐야하긴 하는데

DB에 잘 들어오긴 했다.
그래도 데이터가 부담이 크지는 않아서 3년치를 한꺼번에 처리하고 싶다.
좀 고민을 해보니까 년도에 대한 요청을 묶어서 보낼게 아니고 따로따로 보내야한다.
range_days = 365 * 3 # 3년간의 데이터를 저장하기 위한 일수 그니까 이게 틀린거다.
for comet_name in comet_names:
for year_offset in range(3): # 3년치 데이터를 가져오기 위해 반복
year = current_year + year_offset
start_date = f"{year}-01-01"
range_days = 365 # 1년씩 데이터 조회
# 유성우 정보 가져오기
shower_info_list = get_meteor_shower_info(comet_name, start_date, range_days)
if isinstance(shower_info_list, list):
for shower_info in shower_info_list:
# 중복 데이터 확인 후 저장
existing_info = db.session.query(MeteorShowerInfo).filter(
MeteorShowerInfo.comet_name == shower_info["comet_name"],
MeteorShowerInfo.peak_start_date == datetime.strptime(shower_info["peak_start_date"], '%Y-%m-%d').date()
).first()그래서 이중 반복문 써봄.
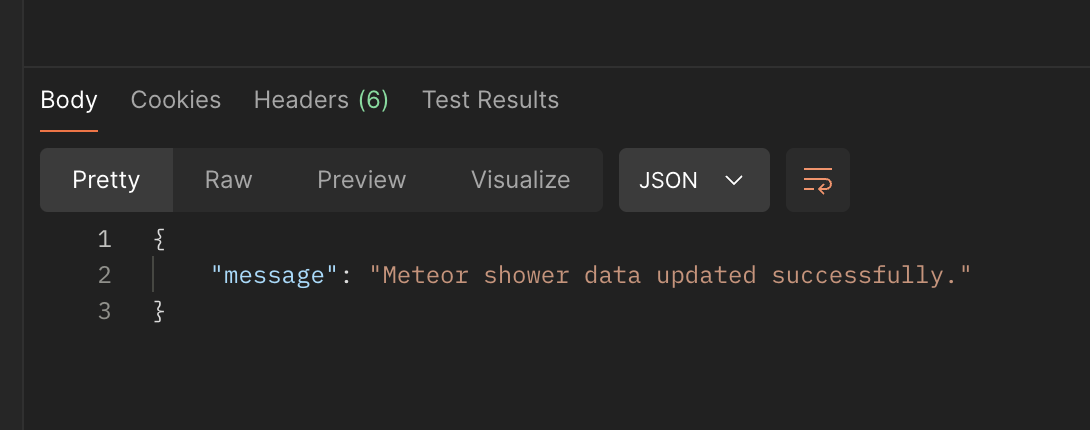
포스트맨에서 성공 메세지 반환 받았고.
로그에서도 특별하게 문제될 건 없어보이고..
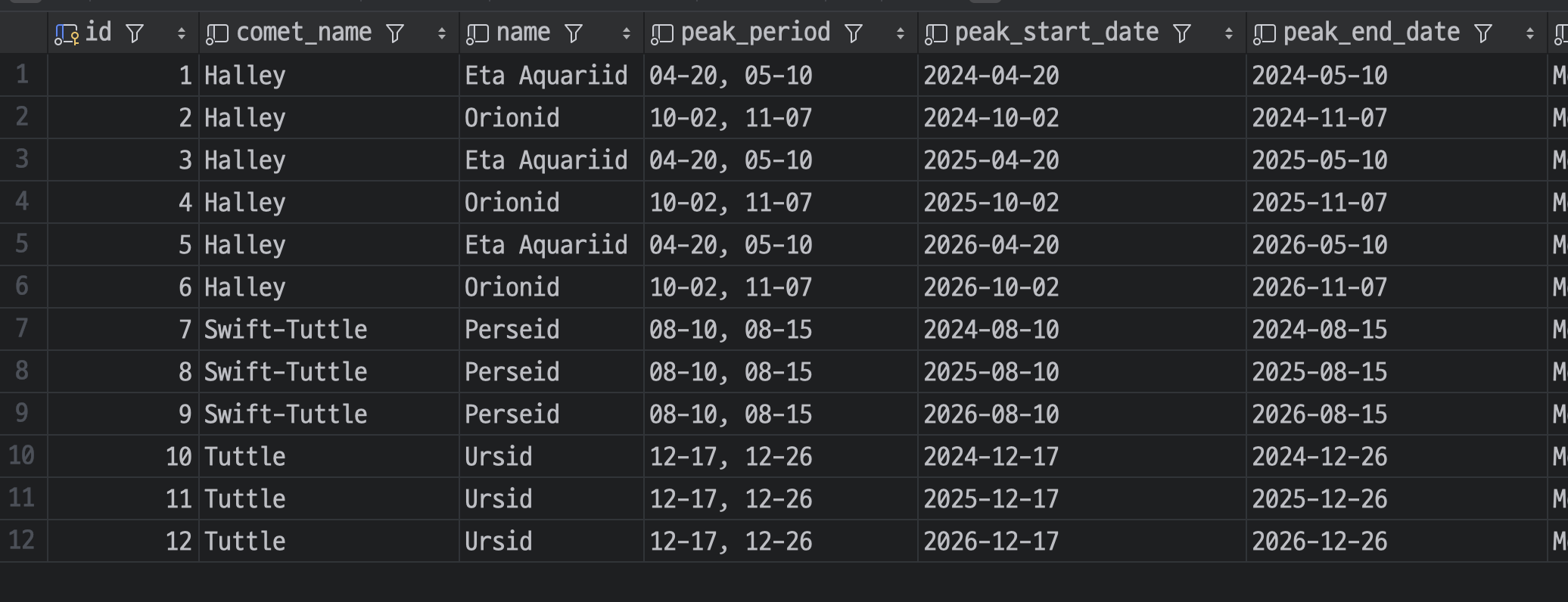
오케이!!! DB 저장 자동화까지 완료다.
그럼 뭐다? 이제 조회도 할 줄 알아야지. 기존 로직에서 요청이 들어오는 경우에 이제는 이 데이터를 뽑아오게 하면 된다.
일단 여기서는 뽑아온 데이터로 가시성 판단을 할 예정이라
meteor_shower_visibility_service.py로 생성을 해주었고.
일단은 간단하게 조회해서 데이터를 잘 뽑아오는지 확인해보자.
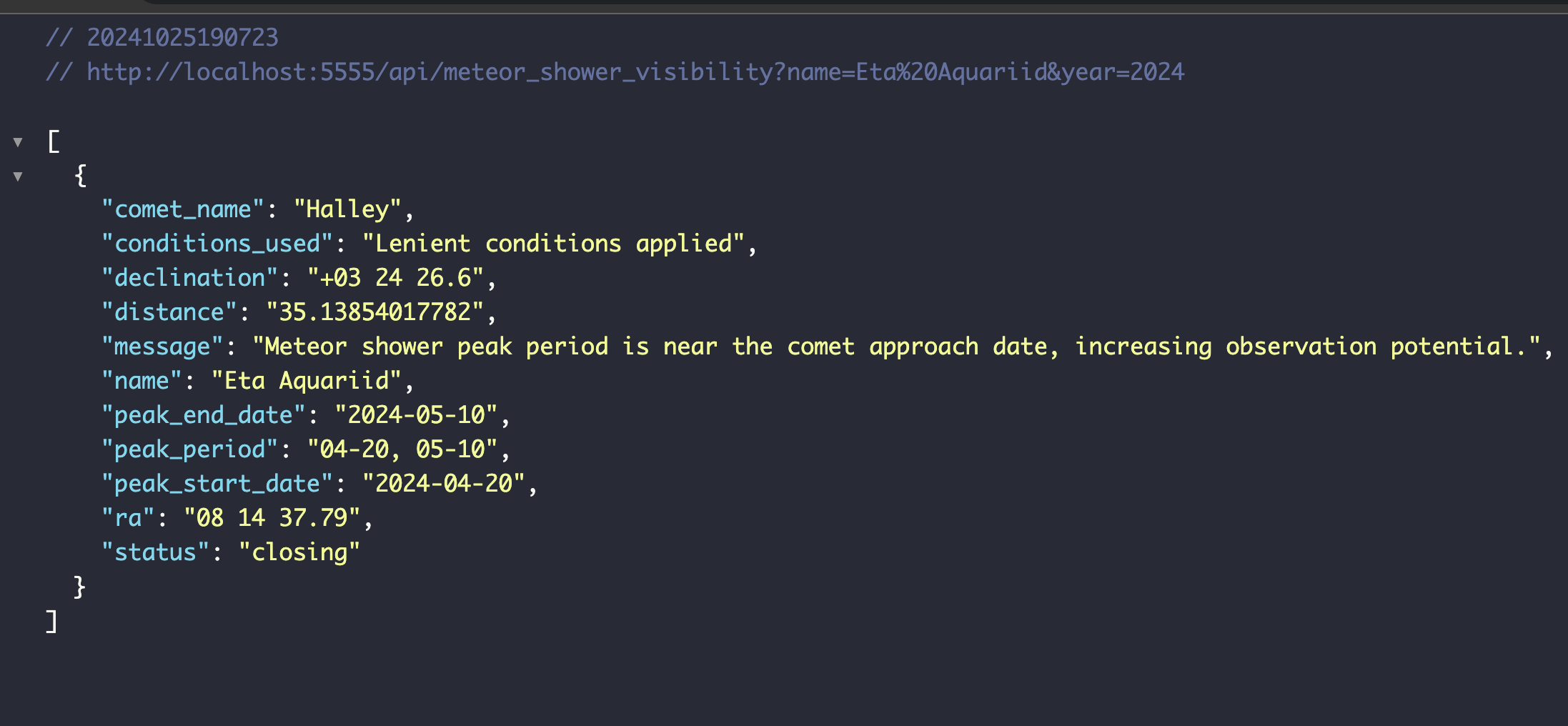
오케이 이것까지 완료 다음으로는 유성우의 가시성 평가다.
이제 끝이 보인다.
'Coding History > Team Project' 카테고리의 다른 글
| 팀플) 별자리 데이터 검증. (0) | 2024.10.30 |
|---|---|
| 팀플) 유성우 가시성 판단 로직 -> 달의 위상구하기까지 (0) | 2024.10.27 |
| 팀플) 기존 행성 데이터 DB 저장, 조회기능 SQLAlchemy로 적용해보기. (4) | 2024.10.25 |
| 팀플) 혜성데이터를 활용해 유성우를 정밀하게 계산하기 위한 전략. (긴 주기의 혜성의 멀어짐과 가까워짐을 판단.) (1) | 2024.10.23 |
| 팀플) 혜성 데이터의 사용 고민. (0) | 2024.10.23 |